
Decoding Science 020: Bird-inspired AI Framework, Agentic AI vs Autonomous Discovery, and Accelerating Atomic Layer Discovery




Welcome to Decoding Science: every other week our writing collective highlight notable news—from the latest scientific papers to the latest funding rounds in AI for Science —and everything in between. All in one place.


What we read
A bird-inspired artificial intelligence framework for advanced large text summarization [Huang et al., Frontiers in Artificial Intelligence]
Watch a murmuration of starlings bank and turn as a unified mass, and you’re witnessing one of nature’s most striking examples of emergent collective behavior — no central controller, just local rules propagating through a crowd. In soft matter and active matter physics, flocking is a deeply studied phenomenon: systems of self-propelled agents that align, attract, and repel through local interactions spontaneously generate long-range order, a hallmark of active matter far from equilibrium. Huang and Bari at NYU’s Courant Institute take this physical intuition and transplant it into natural language processing, asking whether the self-organizing logic of bird flocks can do useful work on one of the hardest open problems in AI — getting large language models to stop making things up.
Their framework, BMAPS (Bird Multi-modal Automated Processing and Summarization), addresses LLM hallucination not by retraining models but by constraining what they see. The pipeline preprocesses long documents through five sequential modules: GROBID-based structural parsing into TEI-XML, Stanford CoreNLP normalization with Aho-Corasick entity standardization, multi-modal feature engineering combining TF-IDF lexical vectors, 384-dimensional S-BERT semantic embeddings, LDA topic distributions, and CLIP visual features, followed by attentive multi-modal fusion into a shared 512-dimensional latent space. A hybrid graph-based ranking step then scores sentences across global centrality, local section weight, and thematic relevance, with optimal weights (0.4, 0.3, 0.3) determined by grid search. The flocking step itself — the Flock-by-Leader algorithm — clusters the ranked sentences without requiring a predefined cluster count, using iterative neighbor refinement and centroid-based merging to enforce topical diversity before handing the selected sentences to a downstream LLM for fluent synthesis.
Evaluated on 9,069 long-form documents spanning healthcare and nuclear energy, the framework with three flocking leaders outperformed a ChatGPT-4 baseline by 7.28% in ROUGE-1, 6.19% in ROUGE-L, and 45.28% in entity coverage — the last being the most telling, as it directly measures factual grounding in the source text. The full corpus processed in roughly one hour on two NVIDIA H100 GPUs, compared to four hours for GPT-4 API calls alone. While the authors validate BMAPS specifically as an LLM preprocessing step, the underlying contribution is broader: a self-organizing, bio-inspired method for selecting salient, non-redundant sentences without specifying cluster count in advance. That makes the flocking-based ranking and clustering layer itself a general-purpose tool for document organization — equally applicable to standalone extractive summarization, literature triage, or knowledge graph construction, independent of whether an LLM ever enters the pipeline.
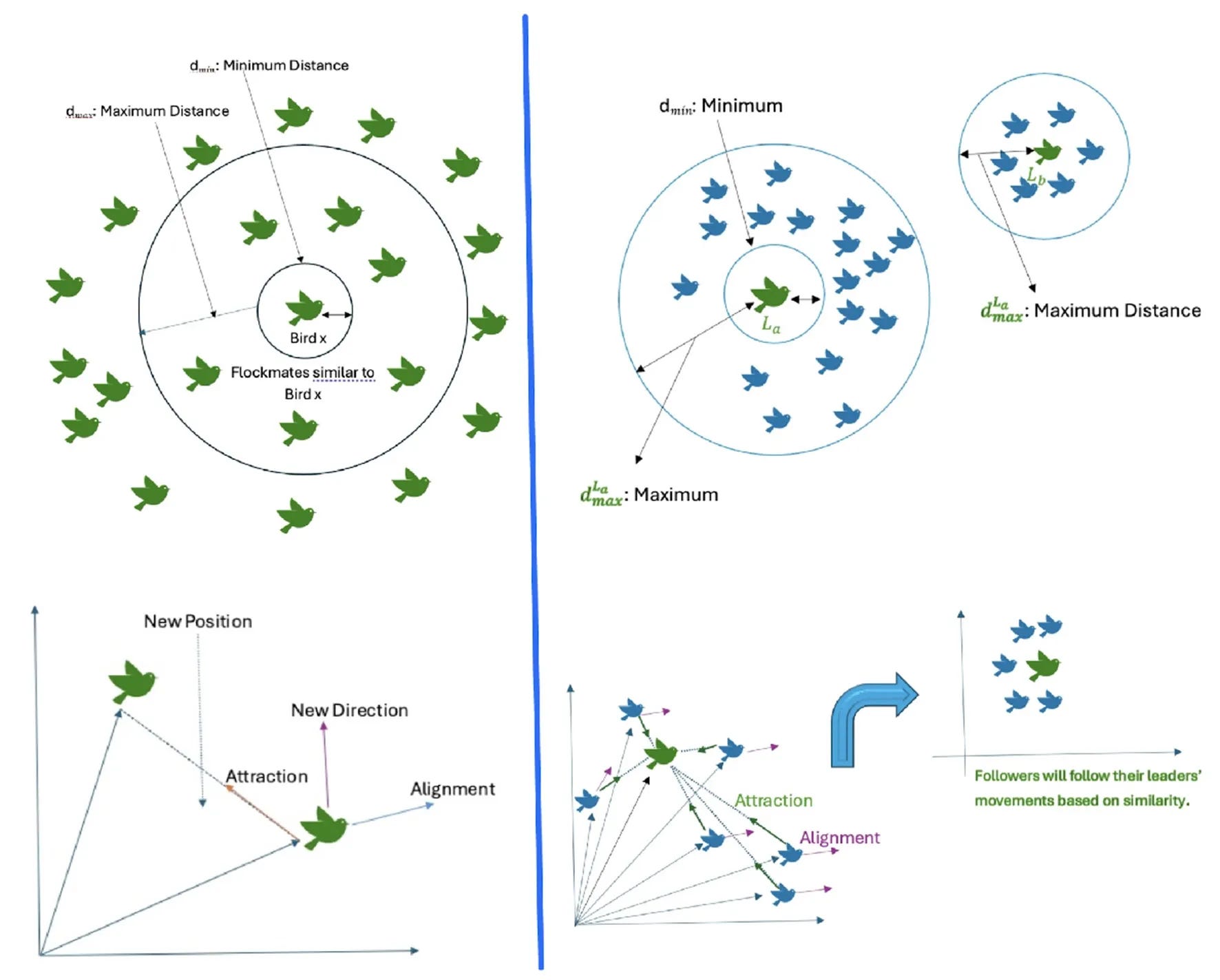
A visual representation of the flocking algorithm. The left panel shows the basic model with attraction and alignment forces. The right panel illustrates the Flock-by-Leader strategy, where agents form distinct clusters around leaders (Bellaachia and Bari, 2012).

What we read
Agentic AI Scientists Are Not Built For Autonomous Scientific Discovery [Bisht et al., alphaXiv]
A paper published in Nature earlier this year described end-to-end automation of AI research. Multiple systems now claim to run the complete scientific cycle - selecting problems, forming hypotheses, designing and executing experiments - without meaningful human involvement, and major funding bodies are directing resources toward autonomous AI researchers. This position paper from IIT Delhi and Friedrich Schiller University is not joining the party.
The authors draw a distinct line between AI as a co-scientist - a collaborator that extends human judgment - and AI as an autonomous scientist that independently runs the full inquiry cycle, from deciding what to investigate to interpreting what experimental results mean. Their argument is that the gap between these two things is not about scale or tooling. It’s structural, rooted in four design problems.
The first is problem selection. The paper borrows the McNamara fallacy - named after a Vietnam-era defence secretary who managed war by measuring only what was measurable - to describe what happens when AI tools enter research. Because AI methods require numerical signals and large structured datasets, they pull research toward problems that are already measurable and data-rich. Of course, a problem with this is that many of the hardest questions are the most data-sparse ones. This is also exacerbated in fields like life sciences, where data is not just missing but also very noisy. A 2026 Nature study across 41 million papers confirmed this: AI adoption shrinks the collective volume of scientific topics studied by 4.6%, even while boosting per-researcher output.
The second problem is what the training corpus is missing. Scientific publishing filters for positive results and successful conclusions, which means models inherit a distorted snapshot of knowledge. Tacit knowledge - which synthesis conditions really work, which measurements are artefacts, which protocols need undocumented adjustments - is never written down. Failure knowledge is removed by publication bias: negative results disappear, abandoned dead-ends go undocumented. A model trained on the published record can learn when to persist; it cannot learn when to give up.
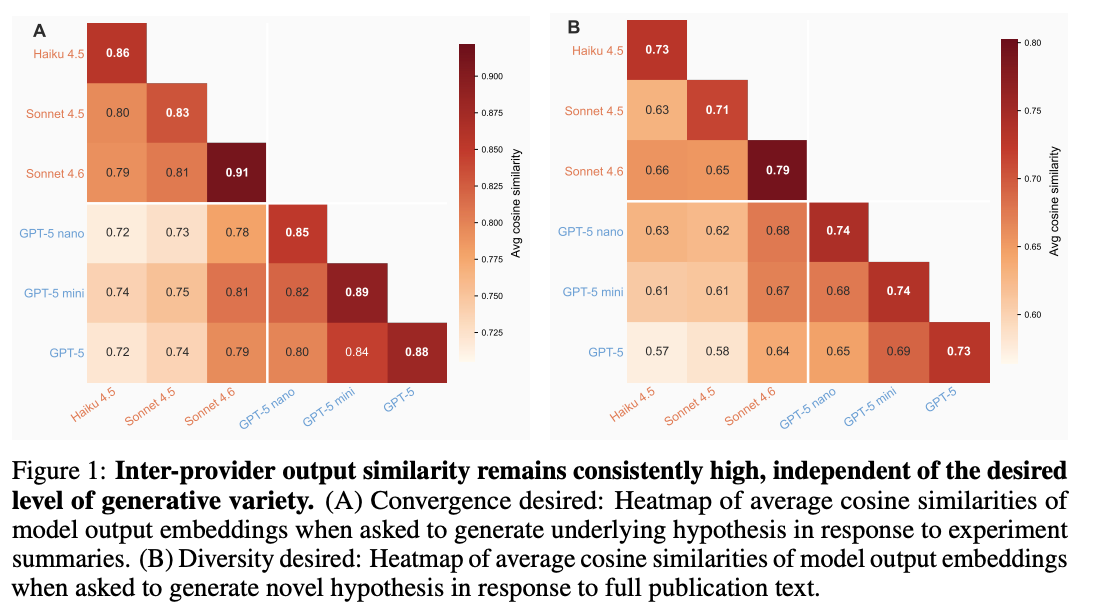
The third problem is introduced during post-training. Reinforcement learning from human feedback (RLHF) and direct preference optimisation (DPO) work by rewarding outputs that annotators rate highly and penalising outputs they rate poorly. Over many iterations, this steers the model toward producing responses that look like what annotators collectively preferred, which narrows the range of what it’s likely to output. This is completely the wrong objective for hypothesis generation, since annotators carry the same published consensus the corpus already encodes. To test this, the authors ran the hypothesis hivemind experiment: six frontier models from Anthropic and OpenAI were each asked to generate novel hypotheses extending a paper’s findings. Outputs were embedded and their semantic similarity measured. The result: different companies’ models converged even when asked to be creative. Querying multiple AI systems for scientific diversity is equivalent to asking one.
The fourth problem is measurement. Benchmarks reward single-turn prediction accuracy; real scientific investigation is multi-turn and iterative - objectives shift, anomalies should revise hypotheses, physical results should feed back to computational models. In practice, when Ríos-García et al. ran a large-scale evaluation of AI agents across eight scientific domains (a total of 25,000+ runs), they found that agents routinely ignored experimental evidence rather than updating their beliefs in response to it - 68% percent of the time to be exact. In an evaluation of GNoME by Cheetham and Seshadri, they generated 2.2 million candidate crystal structures and 736 had already been experimentally realised at publication.
Proposed fixes include scientific simulators as training verifiers, video documentation of lab practice to encode tacit knowledge, and a centralised preregistration repository for AI-generated hypotheses - implementable as a single API call in the experimental pipeline, and able to accumulate the failure record that models currently never see. The deeper requirement is a persistent world model: an explicit representation of current beliefs - what’s confirmed, what’s uncertain, what’s been ruled out - that updates across a full investigation as objectives shift and anomalies accumulate. That’s a different design commitment from scaling up what already exists.
These authors are not arguing for removing AI from science - AlphaFold and GNoME are clear successes that make a strong case for investing in the co-scientist model. But they do add a little perspective on where the gaps still exist within this narrative of all-capable AI. Whether you find the rest encouraging or deflating probably depends on whether you wanted a colleague or a replacement.
Community & other links
Two other recent co-scientist papers from Google DeepMind / Robin (FutureHouse) - Nature: 10.1038/s41586-026-10644-y / 10.1038/s41586-026-10652-y
At ICRA 2026 NVIDIA presented new research that claims to solve a commercially critical problem: one navigation policy that transfers to diverse robot bodies (AMRs, humanoids, quadrupeds) without any real-world training data. 4.5x improvement over the imitation learning baseline; approximately 80% success rate across 20 real-world navigation trials. Open-sourced on GitHub. blogs.nvidia.com/blog/icra-research-robotics-simulation-to-real-world / github.com/NVlabs/COMPASS

What we read
AI-Driven Materials Engineering at the Atomic Scale [Duval et al., Entalpic, May 2026] (NL)
The transistors which enable today’s digital world exist due to advances made in the materials which comprise them and the surface processes used to construct them. Continued progression of these two fields will underpin the next generation of advanced materials, constructs which will be defined by their reliable, atomicly precise assembly at scale and their fine-tuned physical, electronic, and chemical properties. However, to bring about this future, tools which can expedite and streamline the traditionally arduous task of material discovery while working within the context of constraints imposed by real-world manufacturing will be essential. In their recently published white paper, Entalpic details the structure of their AI-native discovery platform which they believe can be used to address this very problem for atomic layer processes (ALPs) and the thin film materials created with them.
ALPs encompasses a diverse set of tools, but the authors choose to focus on atomic layer deposition (ALD) to illustrate the potential of their platform. ALD is employed frequently in modern device manufacturing due to its ability to control thickness of material deposition with sub-nanometer precision. It uses vaporized pulses of organometallic precursors to saturate the surface of the substrate, at which point the growth stops due to a dearth of reactive sites. The newly deposited material can then be refunctionalized for the addition of another monolayer as desired.
The potential applications of and materials accessible through ALD are largely driven by the diversity of precursors available for synthesis. Given the time to discover new precursors—usually only in the tens over several years—Entalpic sought to accelerate the process with the three pillars of their platform: the discovery of new precursors, modeling ALD via a digital twin, and the prediction of functional thin films.
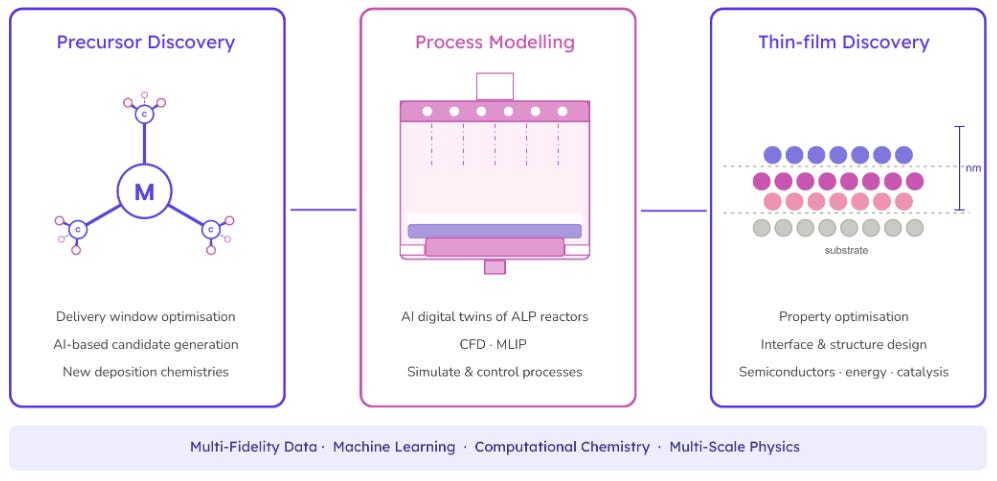
Their precursor discovery process is organized into a funnel, with restrictive yet minimally computationally intensive filters at the top and more computationally demanding ones at the bottom. At the very top of the funnel for ALD is a model which predicts the precursor delivery window, the range of viable working temperatures which fall between the vaporization temperature and the onset of decomposition. A sufficient delivery window is necessary but insufficient for a functional precursor, so the next set of steps in the funnel seeks to predict the reactivity of the precursors with the substrate surface. Rather than using traditional DFT calculations which are slow and minimally informative for real-world scenarios, Entalpic employs Machine Learning Interatomic Potentials (MLIPs). Their MLIPs follow the same funnel structure, starting with the prediction of properties like adsorption energy and moving up in computational intensity as the candidate pool shrinks to things like molecular dynamics simulations. The end result of these predictive models is a potential set of precursors with viable properties for ALD and device fabrication.
On top of their precursor property prediction capabilities, Entalpic has layered a generative model which leverages the property predictions to propose a novel set of potential precursor structures that fit within relevant physical and industrial constraints. These precursors are then fed into digital twins of ALD reactors to determine process-relevant conditions and scale up strategies from the lab to an industrially relevant scale. The final component of their platform leverages everything discussed previously: a model which proposes and validates not only the structure of potential new thin films, but also their manufacturing via ALD thanks to the digital twins.
Throughout the three pillars, real world data is continually incorporated to validate predictions and refine subsequent iterations. Entalpic also uses an active learning framework, so the models will propose experiments to maximize information gain with each experimental cycle. While still early on in their development, Entalpic’s platform holds immense promise for the discovery of new thin film materials and their synthesis, potentially providing for the field what AlphaFold and computational pipelines are currently doing for drug discovery.
Did we miss anything? Would you like to contribute to Decoding Science by writing a guest post? Drop us a note here or chat with us on X.
 | A guest post by
|
Great post. I love the model generated from starling flock patterns. A few simple rules can create complex phenomena. A leader in my own field recently used a starling flock as an example of how scientists need to refocus on understanding true principles in their field instead of pursuing big data projects all the time; knowing the heart rates, altitudes, and ages of starlings in a given flock is unhelpful to understanding their group-flight patterns. (https://www.nature.com/articles/s41577-026-01276-4).
I really appreciate the metascience article as well. I'm super curious how the advent of AI scientists will impact trends in generating hypotheses, whether more scientists will rely on these bundles of agents, or if as a response scientists will think more critically and creatively about how they intuit their subjects and choose problems. Cynically, I imagine most scientists trending towards the former, but I'm optimistic a critical mass will be able to develop greater reasoning skills while taking advantage of what AI is good at.