
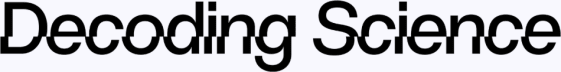
Decoding Science 019: Open-ended Learning Agents in World Models, Autonomous Control of Batch Synthesis, and Polariton-based Photonic Computing




Welcome to Decoding Science: every other week our writing collective highlight notable news—from the latest scientific papers to the latest funding rounds in AI for Science —and everything in between. All in one place.


SIMA 2: A Generalist Embodied Agent for Virtual Worlds [SIMA Team, Google DeepMind]
Most AI assistants live in a box. You type a question in, a response comes out, and the model has no idea - and no way to find out - what the world actually looks like on your side of the screen. What if instead, the AI was in the world with you, could look around, pick things up and find out answers by going to investigate? That is roughly the vision behind SIMA 2, a new generalist embodied agent from Google DeepMind that operates across a wide range of 3D virtual environments.
SIMA 2 is built on Gemini (specifically, Gemini Flash-Lite) and fine-tuned on a large dataset of human gameplay across licensed commercial video games. Like its predecessor SIMA 1, it receives nothing but what a human player would: raw video frames and a text instruction, and outputs nothing but what a human player would use: keyboard and mouse commands. No privileged access to the game’s internal state, no cheat codes.
What makes SIMA 2 a meaningful step beyond SIMA 1 is what gets layered on top of that interface. Because the underlying model is Gemini, the agent can now talk back. SIMA 2 can confirm instructions, ask clarifying questions when a task is ambiguous, and answer questions that require it to go and physically investigate - a capability the team calls “embodied dialogue.” Send it to examine some egg-shaped objects and ask what they’re made of; it’ll navigate over, scan the on-screen text, and report back: “They appear to be plants containing Carbon.” SIMA 1 had no output modality beyond mouse clicks. SIMA 2 has a voice.
Alongside dialogue, SIMA 2 generates internal reasoning before acting - so when given the instruction “go to the house coloured like a ripe tomato,” it reasons: based on the description “ripe tomato,” I identify the red house down the street on the right as the target. Then it goes. This internal reasoning is what unlocks complex multi-step instructions that would have been entirely outside SIMA 1’s scope. Because Gemini’s language understanding is doing the heavy lifting, SIMA 2 can also follow instructions given in French, German, or Mandarin, despite having trained exclusively on English gameplay data. The team also demonstrated multi-modal prompting: hand the agent a sketch or a diagram alongside your text instruction, and it incorporates the image into its understanding of the task - even down to emoji instructions (🪓 + 🌳 = go chop the tree).
On raw performance, SIMA 2 roughly doubles SIMA 1’s success rate across training environments, coming close to human level on both human-evaluated and automatically-evaluated task suites. It’s substantially better at generalising too: tested on ASKA (a Viking survival game) and Minecraft via the MineDojo benchmark - neither of which appeared in training - SIMA 2 outperforms SIMA 1 by over 10 percentage points in each. SIMA 1, confronted with a campfire in a new visual context, fails to recognise it; SIMA 2 spots it at a distance, identifies it tentatively, and navigates to it, narrating each step. While one potential risk of fine-tuning a foundation model on specialised action data can be eroding its general reasoning, the team checked this, benchmarking against code, maths, and STEM tests, and found only modest regression from the base Gemini model.
The most forward-looking part of the paper is on self-improvement. An agent that can get better at new environments without needing humans to generate more training data, is a different category of system - and that’s what SIMA 2 demonstrates. Deployed in ASKA, an environment entirely held out from training, the self-improvement process drives performance from <25% of tasks to over the success threshold to all of them, eventually matching or exceeding experienced human players. The mechanism was as follows:
A Gemini-based task setter proposes instructions dynamically as the agent plays
A separate Gemini-based reward model scores each resulting trajectory on a 0-100 rubric, calibrated to human judgments
The agent then trains on this self-generated, scored experience
No human demonstrations required in the new environment - just the agent, a task proposer, and a judge.
Finally, we come to the real-world implications of this model advancement. The team ran the same process inside Genie 3, a generative world model that produces photorealistic environments on demand from text descriptions. Training on urban environments, SIMA 2’s improvements transferred to natural environments it had never seen. This points toward something more significant: the combination of a self-improving agent inside a world model that can generate limitless new settings is the first working proof-of-concept of open-ended learning, in the sense AI researchers have been gesturing at for years. An agent that doesn’t stop getting better, in a world that doesn’t run out of new things to learn.
Of course, there are still improvements to be made: SIMA 2 still struggles with very long-horizon tasks, has a short effective memory bounded by its context window, and combat remains a weak spot. But the gap between an AI that can talk about the world and one that can act in it - and now teach itself to act better - just got meaningfully smaller.
Community & other links
Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation Tuna-2 achieves state-of-the-art performance in multimodal benchmarks, demonstrating that unified pixel-space modelling can fully compete with latent-space approaches for high-quality image generation. 565 GitHub stars within the first week
AI Identity: Standards, Gaps, and Research Directions for AI Agents AI agents are now running real transactions, workflows, and sub-agent chains across organizational boundaries without continuous human supervision. This creates a problem no current infrastructure is equipped to solve: how do you identify, verify, and hold accountable an entity with no body, no persistent memory, and no legal standing?

What we read
Strongly Nonlinear Nanocavity Exciton Polaritons in Gate-Tunable Monolayer Semiconductors [Wang et al., Physical Review Letters, Apr. 2026]
Light and matter don’t usually mix — but force them together in a carefully engineered cavity, and you get exciton polaritons: hybrid quasiparticles that are part photon, part electron excitation, and entirely fascinating. My PhD is all about micro and nano confinement, so this incredible work on engineering interactions at the extreme nanoscale caught my attention, not to mention the incredible relevance the work has in the current AI boom by demonstrating a new benchmark for nonlinear light-matter coupling in two-dimensional semiconductors.
The device by Wang et al. integrates a gate-tunable MoSe₂ monolayer into a silicon nitride photonic crystal nanobeam cavity with an ultracompact mode volume of ~0.05 μm³ — several orders of magnitude smaller than conventional distributed Bragg reflector cavities. Achieving strong light confinement in all three spatial dimensions simultaneously is central to the result: vertical confinement enhances exciton-photon coupling, yielding a measured Rabi splitting of 33.6 meV via a coupled oscillator model, while tight lateral confinement increases exciton spatial overlap and depletes available exciton states, dramatically boosting polariton-polariton interaction strength through both short-range exciton-exciton interactions and phase-space filling. Electrostatic gating via a WS₂/hBN heterostructure stack allows continuous doping control of the MoSe₂ without introducing optical losses into the cavity, enabling clean transitions between the strong and weak coupling regimes.
Under femtosecond pulsed excitation, the system exhibits pronounced nonlinear polariton responses: the lower polariton branch blueshifts and broadens with increasing pump power, while the upper polariton unexpectedly redshifts at high powers — a consequence of Rabi splitting contraction overwhelming the excitonic blueshift. Most remarkably, all-optical switching is achieved at excitation energies as low as ~4 fJ, several orders of magnitude below prior 2D polariton benchmarks. Pump-probe spectroscopy confirms the switching occurs within ~200 fs at 5 nW pump power, recovering to equilibrium within a few picoseconds, limited by the exciton lifetime.
This work sits at a compelling intersection of quantum photonics and integrated photonic computing — with a clear roadmap toward single-polariton nonlinearities that could power all-optical neural networks and scalable quantum information processing at speeds no electronic architecture can match. I’m personally extremely bullish on the field of photonics, plasmonics, and beyond, if you couldn’t tell, and will be keeping a close eye on the space!
Reaction-aware control of autonomous batch synthesis [Ye et al., ChemRxiv, May 2026]
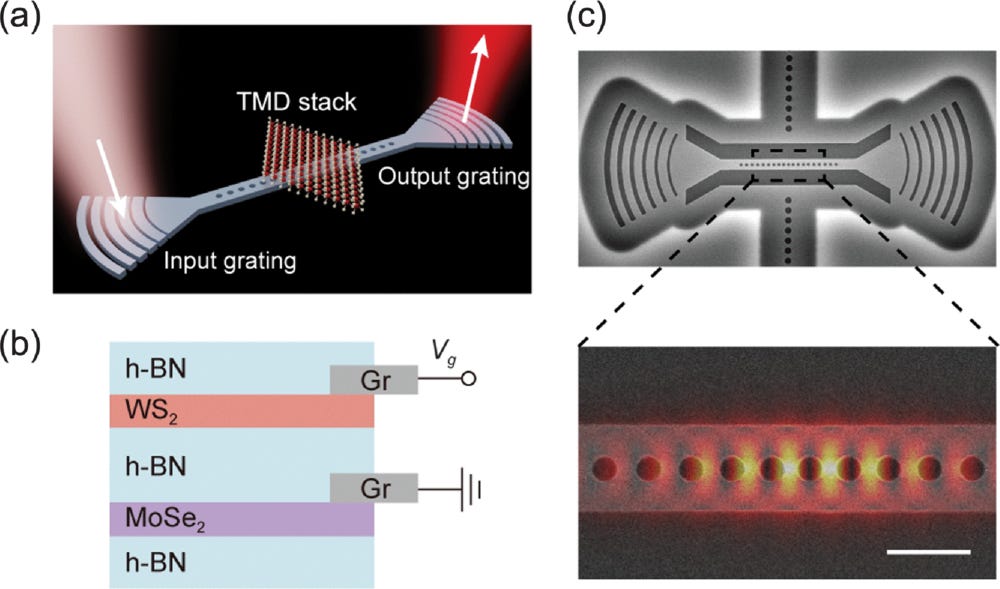
The discovery of new, useful materials is imperative to the continued achievement of humanity’s ambitions, yet the means to do so are vastly antiquated. Historically guided by tedious, iterative experimentation within a prohibitively large combinatorial space, the field of materials discovery is primed for innovation, and with the rise of physical AI connecting robots and automation to wet lab work, the means to do so have never been more accessible. To be effective tools in the lab, these models must have access to sufficient, high quality data, but data of this kind are lacking from batch scale synthesis campaigns since reaction characterization often occurs as a single readout at the end of the run. This singular data point obscures important experimental conclusions, such as how long to monitor a reaction or how frequently it should be sampled. In light of this context, Ye et al. seek to develop a high-throughput, reaction-aware synthesis platform capable of collecting and utilizing in situ kinetic measurements for the optimization of solution-based crystallization reactions.
The synthesis platform from the paper combines a DIY robotic system with in situ UV-Vis to monitor the extent of crystallization, quantifying two important parameters that are used to drive subsequent iterations. The first parameter is the extent of the reaction (𝛼(t)), which is used to inform the execution parameters, such as the measurement interval. Particularly for reactions with rapid kinetics, measurements that are too infrequent can lead to an underestimation of the rate, resulting in “optimized” conditions far from ideal. The other parameter extracted from the UV-Vis data is the nucleation rate constant (kn) which is used to revise the formulation variables such as the concentration of metal precursor. A Bayesian optimization is employed for this process, where kn is used as the objective function.
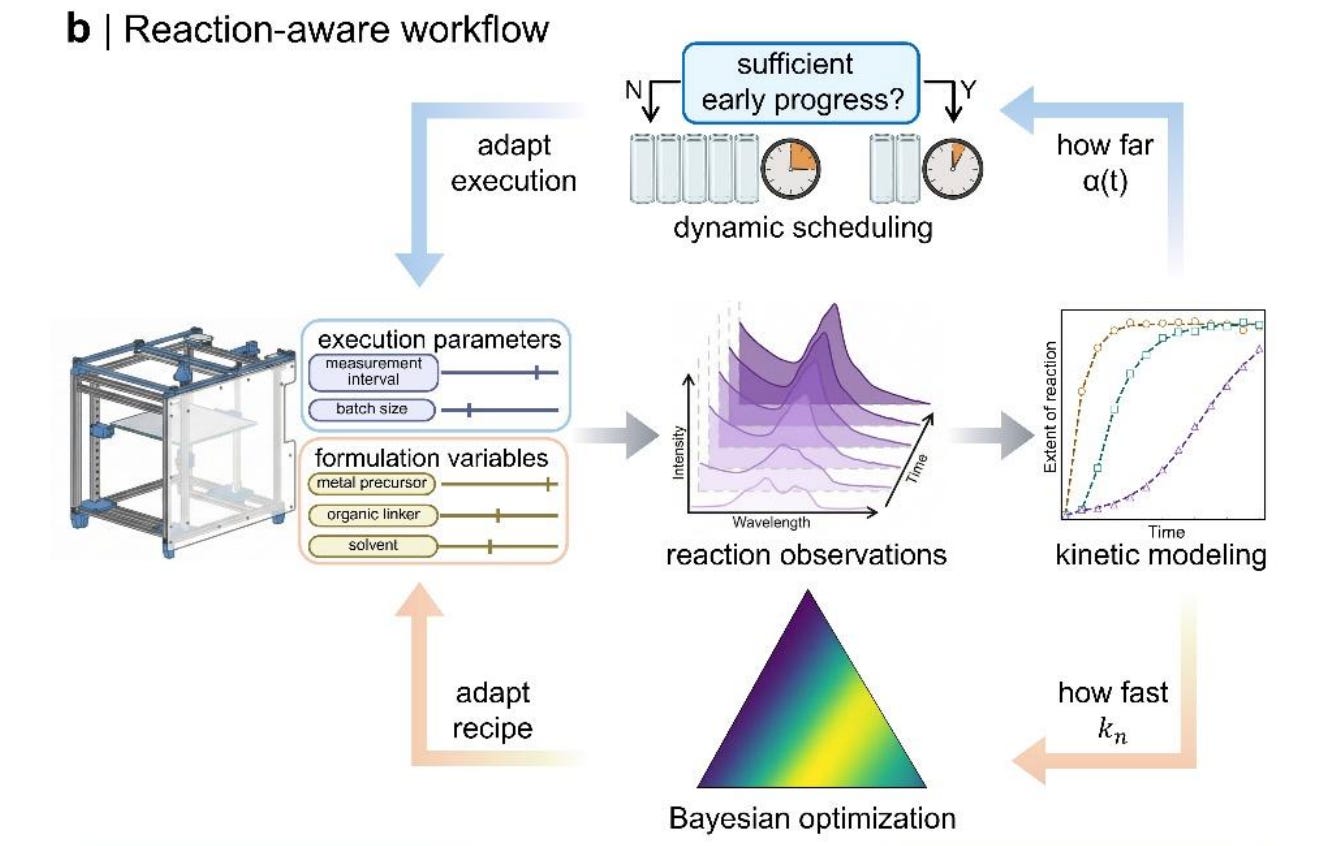
To test their crystallization optimization platform, the authors selected ZIF-67 as a model system. ZIF-67 is a cobalt-based MOF which is highly compatible with the chosen measurement technique as it has distinct optical signatures in its precursor and product forms, caused by a change in coordination around the cobalt from octahedral in the precursor to tetrahedral in the product. After establishing a baseline optimized rate via a traditional 35-sample maximin campaign, the authors tried their platform. Although the experimentation took the same time as the maximin campaign, the optimum kn was found to be 2.33 min-1, 5.4-fold greater than that found through the maximin experiments (0.45 min-1). In addition, their optimized platform reduced the decision interval by 65% and tripled the total number of measurements taken throughout the experiment. With these results, the authors propose this system to be a generalizable tool for the discovery of new materials as well as the optimization of their synthesis. With the modularity of the robot allowing for a diversity of characterization techniques (Raman and IR), the platform is well-suited for many exciting potential applications in the intelligent lab automation space.
Community & other links
2026 Roadmap on AI and Machine Learning for Smart Manufacturing - A formal, multi-institution roadmap authored by 53 researchers and practitioners spanning academia and industry, covering everything from industrial big data analytics to autonomous manufacturing systems and digital twins
Field Trip
Did we miss anything? Would you like to contribute to Decoding Science by writing a guest post? Drop us a note here or chat with us on X.