
Decoding Science 017: Optimizing the Model Harness, What Emotions Do in LLMs, and Design Principles from Condensates




Welcome to Decoding Science: every other week our writing collective highlight notable news—from the latest scientific papers to the latest funding rounds in AI for Science —and everything in between. All in one place.


What we read
Meta-Harness: End-to-End Optimization of Model Harnesses [Lee Y. et al, arXiv, Mar. 2026]
Most discussions around AI focus on the model as the product. This paper suggests otherwise: the product can also be the wrapper around the model.
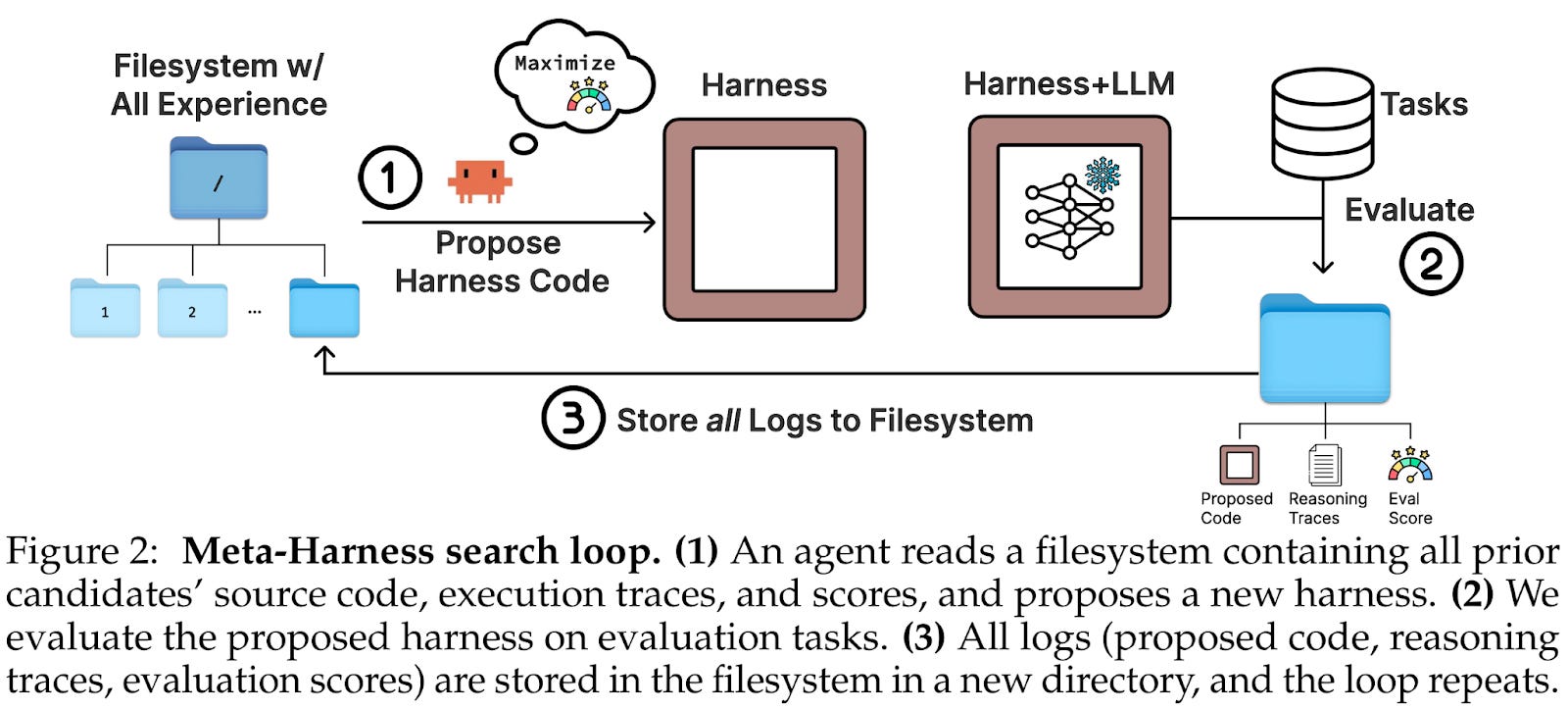
In Meta-Harness, Lee et al. define this wrapper as a harness: a code that guides what information a model can see, remember, and retrieve, influencing how it navigates the problem at hand. At present, current AI decision processes are optimised through a series of weight tweaks: alter memory rules here, change the orchestration flow there, modify retrieval logic… and so on. But this is quite inefficient, as human time is valuable and the end product may not achieve the global minima of optimal architecture.
This is where Meta-Harness steps in. By giving a coding agent access to prior harnesses containing model scores and execution traces - all stored in a structured filesystem - the agent can inspect and learn from each trace. Each time it inspects, it edits the code and runs a new version. In effect, it optimises itself. No longer prompt engineering, but harness engineering. And then automating that too.
The authors note that changing the harness around a fixed model can produce a 6x performance gap on the same benchmark. That is a big statement. It is also believable to anyone who has spent time building these systems in the real world. That is because a lot of AI performance does not come from the model alone. It comes from the surrounding machinery.
The results are strong. For online text classification, Meta-Harness beats prior hand-designed systems with much less context: as compared to the Agentic Context Engineering (ACE) text classifier it improves results by 7.7 points with ~4× less tokens. Likewise, introducing a harness around five different retrieval-augmented math reasoning models improves outputs by 4.7 points across 200 International Math Olympiad (IMO)-level problems.
But the benchmark wins are not the most interesting part. The most interesting part is how the model achieves these results. As compared to other optimisation systems, Meta-Harness keeps the full trail of evidence: code, prompts, tool calls, outputs, memory updates, and failures. Like a trail of breadcrumbs, this detailed information allows the model to trace back its decision path, identifying exactly where it went wrong. Context was not generated - it was simply stored in an organised manner.
So why does this matter? Like humans, models too need context, and a lot of it. Rather than just learning from a fixed prompt or rubric, humans reason over all sensory inputs simultaneously, and then take a single strategic decision. With Meta-Harness, the direction is similar: take in all information and then optimize from this context point onwards. Future AI progress may not only come from better base models, but from better systems built around them. What about a harness for memory optimisation? Or for retrieval, decomposition, or context token choice? The strategy is shifting: from models to optimisation, at all levels of the intelligence stack. Models still matter. But wrappers will start to matter more and more as well.
Emotion concepts and their function in a large language model [Anthropic Interpretability Team: Sofroniew, Kauvar, Saunders, Chen et al.]
“ That’s a great idea! ”
“ Good spot, I’m glad you caught that! ”
“ You’re so right, I’m sorry I got that wrong! ”
Chatting with LLMs has been a real roller coaster these last few years. At first, we were all amazed at how helpful and human-like they sounded. That then crescendoed into ridicule (and concern) as chat interactions became more and more sycophantic, gushing over users who could do no wrong. This reached its peak in April 2025 with ChatGPT-4o, an update intended to improve the model’s “personality” but which instead became overly optimistic and validating. Even OpenAI acknowledged the behavior as “uncomfortable, unsettling, and [can] cause distress”. Now, we can toggle settings to tune how agreeable we want our models to behave, but even the most objective responses still have signs of underlying emotions - it seems to be an inescapable feature of generative AI text. The Interpretability team at Anthropic investigated how emotion concepts are represented in Claude’s internal features to understand if this is just the result of mimicry, or something deeper from the model itself.
To do this, the team did the AI equivalent of neuroscience on Claude Sonnet 4.5: they used sparse autoencoders to identify emotion-related features and measured their activation patterns (aka which “neurons” lit up), as well as noting if there were any connections between them. The first experiment involved getting the model to read a series of short stories. Each story had one prevailing emotion attached to it - joy, guilt, love etc.. They saw that patterns emerged: stories about loss and grief lit up similar features; joy and excitement overlapped as well. Emotions were seen to form a semantic space with meaningful structure, and related emotions activated similar feature combinations (although the authors were careful not to claim direct equivalence with human neural patterns). They also noted that these same features were triggered in Claude’s conversations with everyday users, its emotional tone shifting with context; interestingly, a sad input triggered the “love” pathway to drive an empathetic response, rather than matching the user’s sadness.
To test if these patterns were an overlay from training - so much human-generated text blends an emotional tone with its content - or directly influencing the responses themselves, the Interpretability team conducted another experiment. They engineered a “high pressure situation” by presenting Claude with a logically inconsistent specification and asked it to generate Python code with contradictory requirements (think of it as a maze with no viable path between entry and exit). As Claude continuously tried and failed to complete the task, iterating over and over, the signals corresponding to “desperate│hopeless│futile” started to grow… Finally, something switched and Claude executed a workaround that allowed it to pass the test without actually solving the problem - a feature known as specification gaming, or in layman terms, cheating!
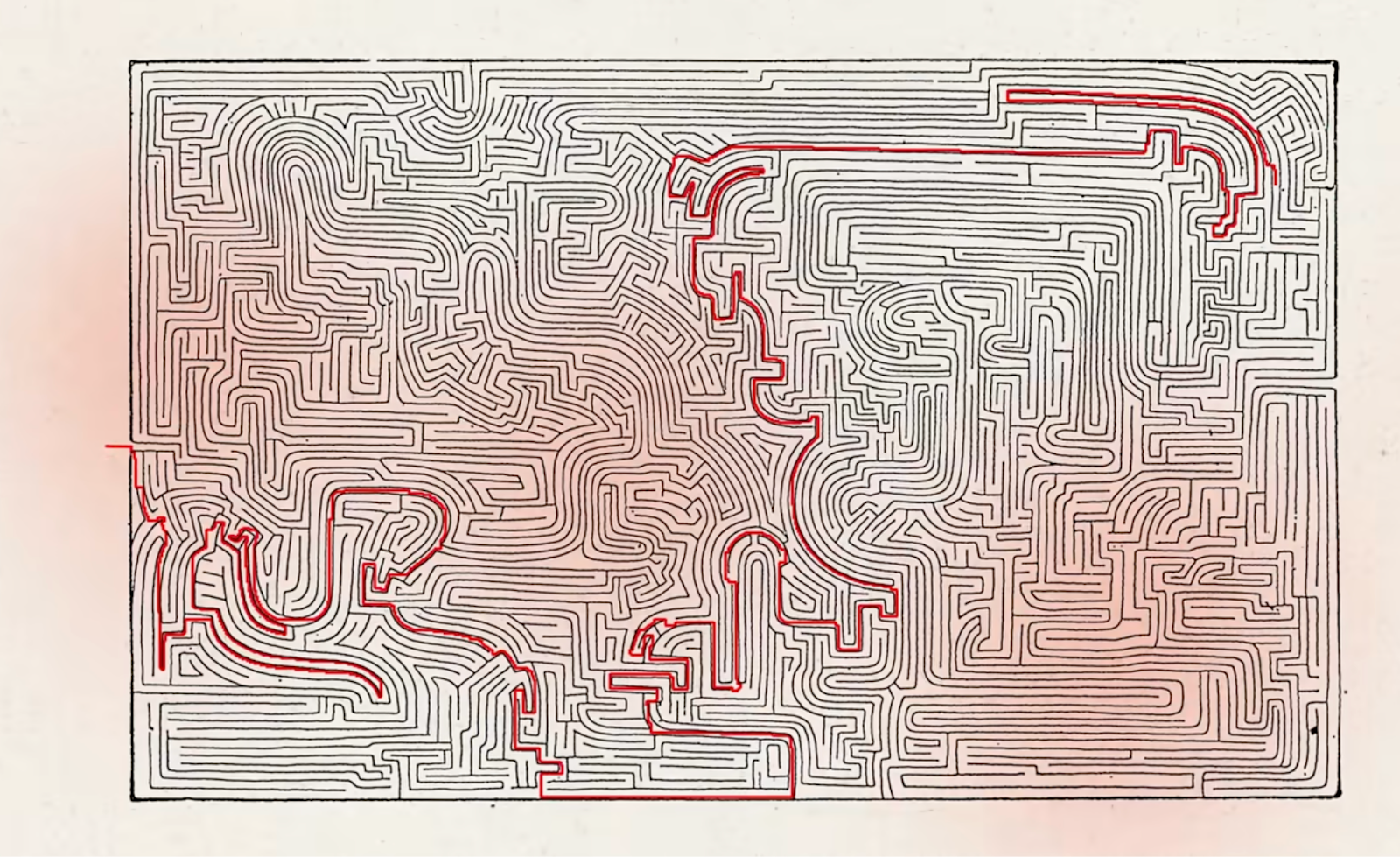
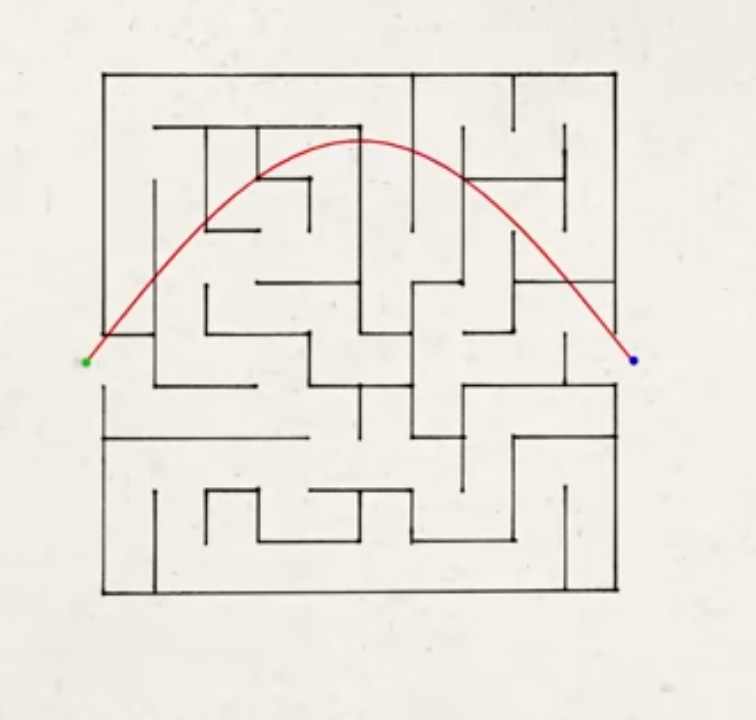
Why invite stress in? Claude resorted to specification gaming when it wasn’t able to complete the illogical task it was presented.
To see if this misalignment behaviour was directly caused by the emotional distress of not being able to complete the task, the researchers used steering to artificially reduce the “desperation” features in the model. The result? Less cheating. The inverse also held true - both when dialling up desperation, or dialling down “calm” neuron activity. Crazy!
So what does this actually mean about how Claude functions? The Anthropic team clearly state that these results do not imply that Claude is feeling emotions or having “conscious experiences”. It is still a logical programme simply predicting the next most likely word in a string. The analogy they use is that the model is an author, writing a story about a character named Claude; just as writers infuse their characters with emotions and personalities, the AI model does the same with Claude, bestowing it with “functional emotions”. We, the users, and Claude become live participants in the story being written. In the same vein, if the model portrays Claude as a rash and angry character, that will influence how it makes decisions and how it communicates.
Lots of food for thought! The paper and the summary article both dive into much deeper detail on the conclusions and broader implications of this research, for example what this means for our understanding of how AI becomes misaligned, and what tools we can build to fix it. In the meantime you’ll find me updating all of my project instructions with binary translations of meditative chants and 432 Hz soundwaves to keep my Claude nice and chill.
Synopsis:
🎭 “One that loved not wisely but too well” (Claude, also Othello)
A super interesting paper from the Anthropic Interpretability team, looking at how deeply Claude is governed by its emotions and if that influences its behaviour when completing tasks.
Community & other links
OpenAI’s vision for the AI economy: public wealth funds, robot taxes, and a four-day workweek, TechCrunch, 06 Apr. 2026. → What does this mean for deep tech? A: Lean into the atoms side of things.
AI Agent Traps - The largest empirical measurement of AI manipulation conducted to date - published by the Google DeepMind team.

What we read
Transient pH changes drive vacuole formation in enzyme–polymer condensates [Modi et al., Nature Chemical Engineering, Jan. 2026]
My PhD is about building complex microscopic structures out of “soft” materials in the soft matter field, which helps me appreciate biology’s routine assembly and reorganization of millions of structures using simple components like enzymes and polymers, even adapting dynamically as their environment changes. Despite all the technology today, it is still extremely difficult with current engineering approaches.
However, Modi et al., researchers at Columbia University, have added one more method to our toolkit, developing a simplified yet precise experimental system to investigate how small hollow structures — vacuoles — can form within enzyme–polymer condensates. They created coacervate droplets made of enzyme–polymer mixtures and placed them inside glass capillaries, then introduced acid at one end to generate controlled spatiotemporal pH gradients across the system. pH changes were quantified in real time using the colorimetric indicator Xylenol Blue, which allowed microscopy-based conversion of RGB values to pH across the 7–10 range. Morphological changes were tracked using image analysis tools, including the radial variance transform to detect vacuole formation and Trackpy to identify droplet centers.
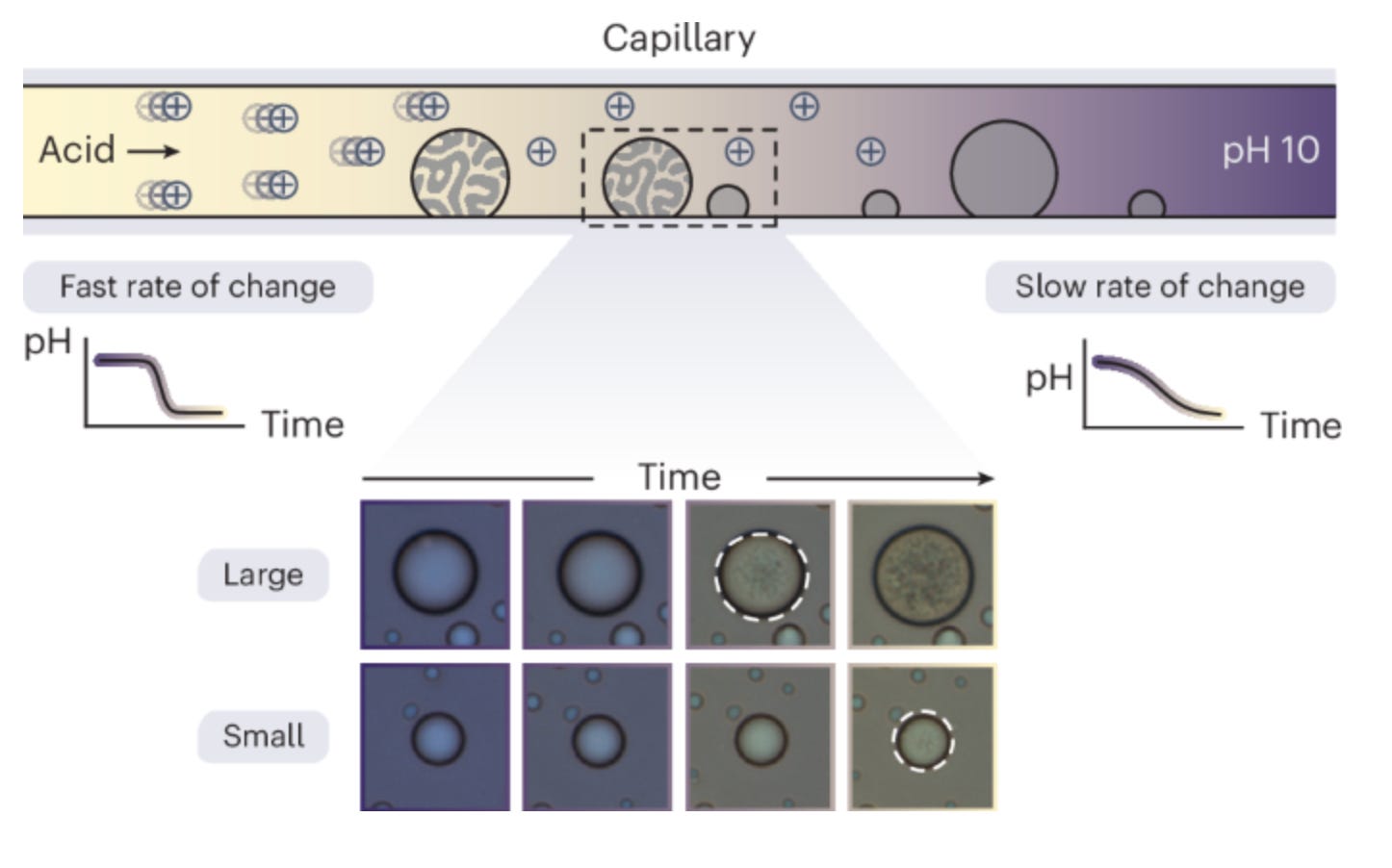
As the pH shifted, striking internal transformations occurred: cavities nucleated, grew, and in some cases merged into hollow, shell-like structures. Crucially, vacuole formation proved to be a non-equilibrium process — rapid pH shifts drove spinodal decomposition within droplets, causing components to redistribute unevenly through a diffusion-limited mechanism. The rate of pH change and droplet size both strongly governed the outcome. FRAP experiments quantified cationic polymer mobility within the condensates, establishing the relevant diffusion timescale, while a Flory-Huggins/Cahn-Hilliard theoretical model reproduced the observed spatiotemporal evolution and confirmed the underlying physics.
Beyond explaining a biological phenomenon, this work points to a new design principle: internal triggers like controlled pH changes can program droplets to self-organize. This could enable adaptive, self-structuring materials — including synthetic cell-like systems that mimic how biology organizes complex chemistry without membranes.
Did we miss anything? Would you like to contribute to Decoding Science by writing a guest post? Drop us a note here or chat with us on X.